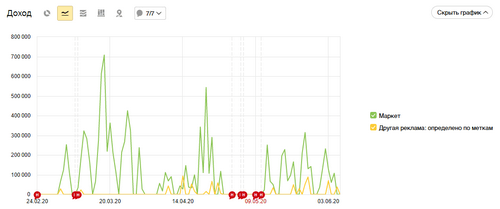
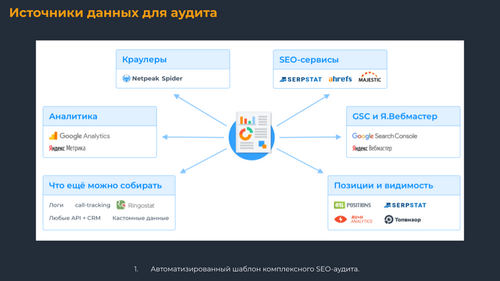
Мы собираем данные быстро из множества доступных нам источников. Шаблон определяет ошибки, точки роста, визуализирует данные. Можно использовать также Data Studio – тогда данные автоматически подтягиваются для формирования красивых отчетов.
Вам остается сделать выводы и помочь клиенту увидеть проблемы, их решение и точки роста, т.е. качественно презентовать вашу работу.
Часто бывает, что вы собрали очень много данных по сайту, есть выгрузки из 10 сервисов, 50 документов или вкладок браузера. Затем вы начинаете копаться в каждом из них отдельно и не видите полную картину происходящего. В подобном хаосе зачастую не получается сделать правильные выводы, приоритизировать задачи и ничего не упустить.
Я Growth Hacker в компании Netpeak Software. Мы разрабатываем программы для SEO-специалистов и вебмастеров. На конференции Baltic Digital Days 2019 в рамках SEO-потока я выступал с докладом: «Как перестать убивать время на сбор и обработку тонны данных для SEO-аудита?».
В докладе я поделился многофункциональным инструментом, на создание которого меня вдохновил опыт нашей компании в разработке уже нескольких программ, общении с тысячами специалистов по всеми миру и с множеством проектов. Это не просто шаблон SEO-аудита, он позволяет найти точки роста, проблемные зоны сайта и визуализировать данные, что сможет вам помочь на этапе пресейла.
Концепт процесса комплексного SEO-аудита я показал на примере интернет-магазина, однако он применим ко всем видам сайтов.
Отмечу главные преимущества моего подхода:
- Комплексность. Получаем данные о множестве факторов ранжирования (и не только) из различных источников в одном месте.
- Скорость. Собираем данные и находим инсайты, проблемы и точки роста за минимальное количество времени.
- Доступность и простота. Каждый может применять этот подход, можно даже делегировать его сотрудникам (Junior-специалистам), потому что он детально описан в мануале.
- Кастомизируемость. В любой момент времени вы можете что-то добавить, что-то убрать, использовать какую-то уникальную наработку.

1. Собираем данные по сайту воедино, чтобы ничего не упустить
Я хочу предложить решение этой проблемы в сервисе Google Таблицы, так как он простой, мощный и бесплатный. Наиболее полезен он будет для проектов до 30 тысяч страниц, так как есть ограничения по размеру документа. Если вы работаете над очень большими проектами, тогда сам подход будет вам полезен, но инструментарий в виде Google Таблицы не подойдет для вашего количества данных.
В таблицу я собираю все доступные данные и консолидирую всю информацию по странице из различных источников.
Вы можете использовать ее как уже готовый шаблон для работы или персонализировать под ваши процессы – «прикрутить» свои дополнительные модули / проверки / отчеты.
2. Алгоритм работы с шаблоном

Повторяем эти четыре шага с определённой периодичностью. Каждый шаг детально и односмысленно описываем в регламенте работы, минимизируя шанс что-либо упустить, сделать неправильно. Пройдемся детальнее по каждому шагу.
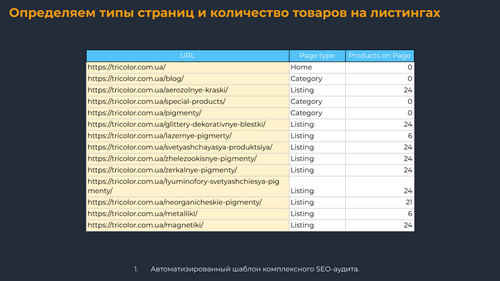
Определяем типы страниц и количество товаров на листингах
Итак, у нас есть сайт (я для примера использую интернет-магазин tricolor.com.ua), который нужно просканировать и разметить типы страниц. В случае с интернет-магазином стоит дополнительно подтягивать количество товаров. Для этого можно использовать данные парсинга по микроразметке или другое условие кастомного парсинга.
Страницы нужно разбивать по типам и/или категориям, чтобы потом удобно сегментировать данные. Тип страницы и/или категорию чаще всего можно определить по URL. Например, карточка товара находится по URL-адресу, который содержит сегмент /product/. Когда так нельзя сделать, используйте парсинг, чтобы найти на разных типах страниц уникальный код, который и отличает этот тип.
На различных проектах типы страниц и категории будут отличаться, поэтому определите изначально, как вы хотите сегментировать страницы. Например, если на сайте есть листинги для различных городов, тогда есть смысл добавить тег города. Если есть страницы, которые содержат все товары определенного бренда, тогда есть смысл добавить тег листинга бренда.
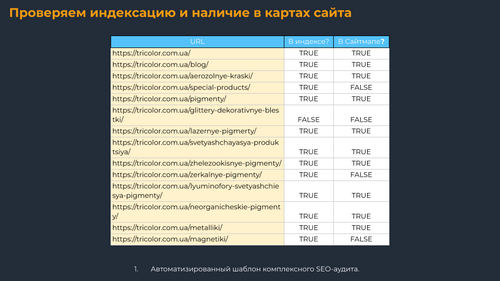
Проверяем индексацию и наличие страницы в картах сайта
Наличие страниц в индексе поисковых систем можно проверить с помощью Netpeak Checker, Rush Analytics, overlead.me, других вариантов.
Но проверка индексации стоит денег. Поэтому можно немного сэкономить на этой проверке и сразу считать проиндексированными страницы, которые получали показы или трафик за последнюю неделю.
Когда вы анализируете страницы, которые не попали в индекс, нужно сразу проверить, есть ли они в карте сайта. Дополнительно просканируйте все страницы из карты сайта, чтобы найти среди них проблемные (битые, редиректы, закрытые от индексации), которые затем замените на целевые.
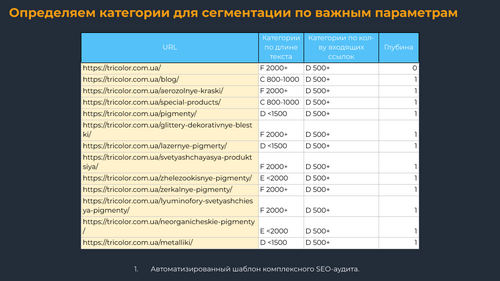
Определяем категории для сегментации по важным параметрам
Сюда подтягиваем основные On-Page данные (внутренние входящие ссылки, скорость ответа сервера, глубину URL, количество слов, инструкции индексации, метатеги, другие). Советую сразу сделать категории по этим показателям, чтобы удобнее сегментировать данные и строить диаграммы.
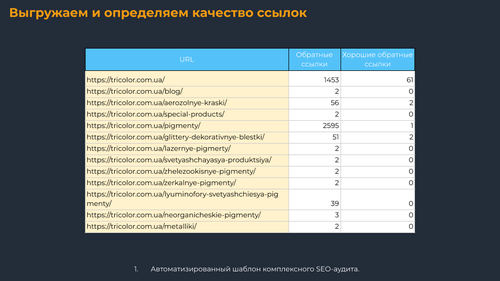
Выгружаем и определяем качество ссылок
Переходим к внешним факторам. Выгружаем данные по ссылкам из Serpstat, Ahrefs, MegaIndex, сводим количественный показатель ссылок на каждую страницу. Затем важно видеть, сколько из них хороших, потому нужен столбец, который отфильтрует сквозные ссылки,, некачественные (DR, UR, другие по вашему условию).
Дополнительно это даст понимание о заспамлености страницы некачественными ссылками.
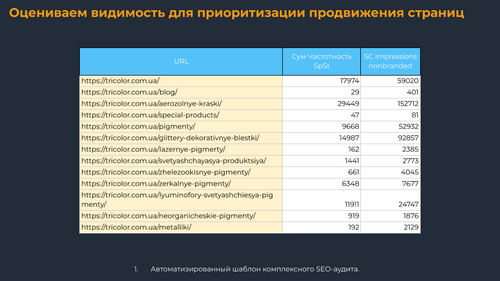
Оцениваем видимость для приоритизации продвижения страниц
Если у вас собрана чистая семантика, по которой вы собираете данные по позициям и частотности – отлично, импортируйте ее в таблицу, чтобы определить видимость каждой страницы.
Если семантики нет (например, вы на этапе пресейла или анализируете конкурента), тогда можно данные по ключам выгрузить из сторонних сервисов, как это сделал я. Такими сервисами могут быть Serpstat, Spywords, keys.so, Google Search Console и/или Яндекс.Вебмастер, если есть доступы.
Например, ниже я вывел суммарную частотность запросов страниц и показы из Search Console. По этим показателям я могу приоритизировать страницы.
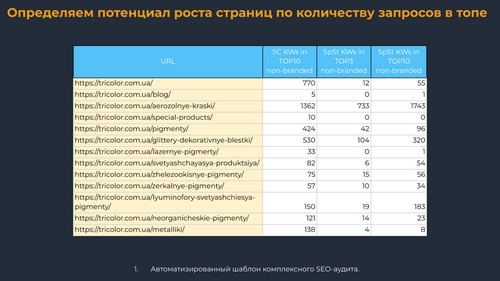
Определяем потенциал роста страниц по количеству запросов в ТОПе
Дальше считаем количество ключей, по которым страница показывается в ТОП 3 и ТОП 10, чтобы оценить потенциал роста страницы. Позиции можно изменять в зависимости от текущих позиций проекта, например, для кого-то это будет ТОП 10 и ТОП 20. Важно учитывать именно небрендовые запросы.
Подтягиваем данные по трафику и конверсиям
С помощью расширения Google Analytics для Google Таблиц я выгружаю данные по трафику и конверсиям в документ, а потом консолидирую со страницами с помощью VLOOKUP (вертикальный поиск, ВПР). Важно смотреть не только трафик, но и конверсионность.
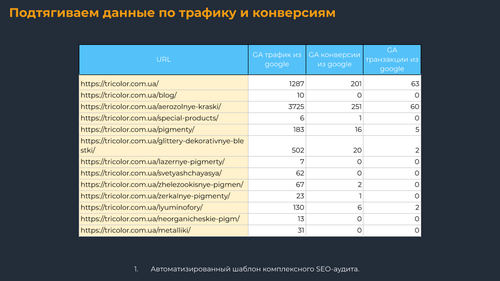
Итого у нас есть минимальный набор данных для комплексного анализа страниц, который можно дополнить логами сервера, данными из CRM или релевантными вашему проекту и процессам параметрами.
Чтобы упростить внедрение такого подхода в ваши процессы, я подготовил детальный пошаговый мануал процесса сбора данных. Копируйте себе, дополняйте, модифицируйте под свои задачи, процессы, инструменты. Буду рад, если дадите обратную связь в комментариях о том, что еще хотели бы видеть в отчете и регламенте.
Используем API для ускорения сбора данных
Вы можете выгружать данные вручную и потратить на это много времени, а можете собирать их по API за считанные минуты, особенно из сервисов Google Analytics, Я.Метрики, Google Search Console, Я.Вебмастера. Я описал в регламентe действия для выгрузки данных + нюансы для обхода сэмплирования.
P.S. Для Excel есть надстройки, которые выгружают данные (PQGoogleAnalytics и PQYandexMetrika от Максима Уварова).

Алгоритм добавления новых данных
Данные из разных сервисов нужно собирать на новые листы в формате URL → Данные, чтобы потом использовать VLOOKUP (он же ВПР, вертикальный поиск) и подтягивать в основную таблицу информацию по каждому URL.
Данные, которые вы не собираетесь периодически заменять (например, по ссылкам), после подтягивания формулой советую скопировать и вставить только значения, чтобы не загружать сильно таблицу.

Небольшая фишка: если в сервисе нет нужного вам отчета, но есть API, на помощь всегда приходит скрипт ImportJSON, который поможет распарсить API-ответ прямо в Google Таблицы.

Чтобы посмотреть, как это выглядит, перейдите в документ с шаблоном такого отчета.